Scraper API helps you to scrape any website bypassing all rate limitations. Ability to simulate originating IP from any country. Fast and simple.
Web scraping involves complex routines like simulating a browser's behavior and dealing with rate limits of the destination site. Our Scraper API allows many features of simulating a desktop browser's behavior by giving you the ability of:
- Setting the referrer and user-agent,
- Selecting the originating country where we fire the HTTP request,
- Adding cookies to the request header,
- Setting any HTTP header (even the non-standard ones),
- Setting HTTP Auth username and password.
- APILayer's Scraper API is one of the versatile and affordable ways to collect any data from the web.
Important!: This API does not simulate a browser and render the results, so it can't scrape many client heavy pages and also bypass some bot prevention tools. Check out our Advanced Scraper API built specifically for this purpose. This API is intended to be a cost efficient alternative for basic scraping needs.
How to use CSS Selectors?
When a remote web page is fetched by default, whole HTML is returned as String. If you wish us to parse the HTML automatically and just return a specific portion of the data you can set a selector parameter and the API will parse the HTML and just return the desired info. See the following example:
curl --location \
--request GET 'https://api.apilayer.com/scraper?url=apilayer.com&selector=%23logoAndNav%20a.navbar-brand' \
--header 'apikey: API KEY'
Please note that the selector parameter is URLEncoded since some CSS selectors (such as # character) may confuse the URL parameters. The result for this query is below. Please note that not the whole apilayer.com homepage is fetched. Instead just the A tag with the logo exists in the returning data, thanks to the #logoAndNav a.navbar-brand CSS selector.
{
"data-selector": [
"<a class=\"navbar-brand\" href=\"/index\">\n <img src=\"https://.../assets/logo/logo.png\"/>\n</a>\n"
],
"headers": {
"Date": "Sun, 06 Sep 2020 09:48:32 GMT",
"Content-Type": "text/html; charset=utf-8"
},
"url": "http://apilayer.com",
"selector": "#logoAndNav a.navbar-brand"
}
Image files scraping
The Scraping API is capable of fetching the image files and returning them back to you. Just point the url to an image file and see for yourself. This is one of the most powerful features of this API, which is quite rare among our competitors.
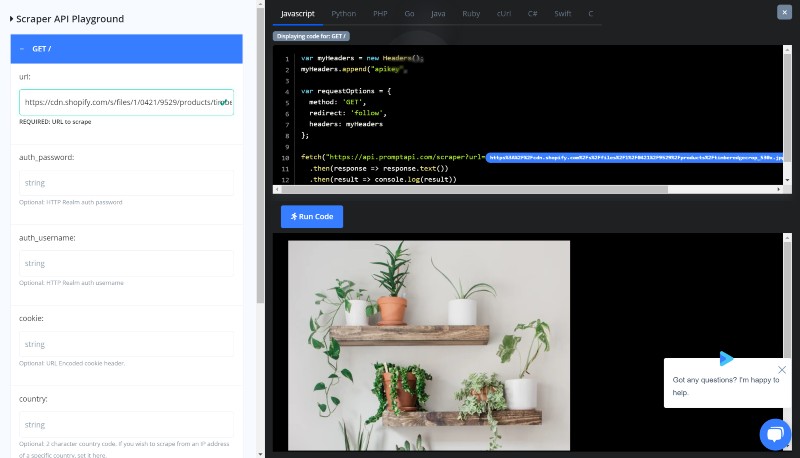
Although it can also download JSON files, TXT files and other text formats. it doesn't support application/octet-stream and any other binary formats because of security and scalability concerns.
Rotating IP addresses
We use anonymizer proxy servers, as well as our own infrastructure to change the IP addresses, as well as the HTTP request header information each time you make a new request. We utilize more than 1 million "data center" IP addresses from over 100 countries to route your request through.
There are many reasons why you need this API for web scraping:
- It helps you to overcome IP fingerprinting and rate-limiting problems
- It saves you from getting your original IP banned due to high volume of requests
- Ability of setting originating country allows you to see geography specific content
Setting Custom HTTP Headers
You may wish to set your custom HTTP Headers with your request and our Scraper API lets you do so. You can set any header by just prefixing X- to the name of the header and API will remove the X- prefix and pass it to the remote site. For example if you wish to set your custom User-Agent, Referer and Content-Type take the following example (if nothing is set, we auto generate these headers)
curl --location --request GET 'https://api.apilayer.com/scraper?url=apilayer.com' \
--header 'X-Content-Type: application/json' \
--header 'X-User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0' \
--header 'X-Referer: https://www.google.com' \
--header 'apikey: YOUR_APILAYER_API_KEY'
As you see Content-Type, User-Agent and Referer headers are prefixed by a X- string. You can set any header as you wish, such as Cookie, Api Key, Languages or anything you desire. Take a look at a full list of HTTP Headers on Mozilla site.
Can I scrape Google Search Results with it?
This API is not triggering a headless browser in memory, so it is not suitable for Google Search results scraping. That is a much more complicated task then just asking for HTML content and parsing it. Check out this blog post on doing it yourself or simply check out the Google Search Results API that was built just for this purpose.
Google Search Results API will fetch and parse the results in JSON format, from any country with no worries and even fetch the ads!
Also you may wish to check out our Advanced Scraper API which can simulate a real browser, render the web pages (Angular, React, Vue is also supported), execute any JS code and return its results.
For all other programming languages see the documentation tab for more information.
Privacy
Except for obvious legal purposes, we do not store any information on our servers. We'll just work as a proxy and we will never inject any code in response nor interfere with your data in any way. We'll just take the scraping request, fetch data from the remote server and pass it back to you in JSON format. That's it!
Common areas web scraping used for:
Every individual person or business owner has their own reasons to use the data that is gathered but below is the common areas where web scraping plays important role:
- Price monitoring website for comparison
- E-commerce: Competitor monitoring, Market analysis
- Collecting stock market data
- Real Estate Listing
- Machine Learning : to supply a wide variety of data to train and test your model.
- Brand protection
- Market research
- Lead generation
Is web scraping legal
Web Scraping is in the legal-gray area and it all depends if you have the right intentions to use the scraped data. Most of the data on the websites are open for public consumption and can be copied by other parties unless otherwise stated in the website copyright and term of use statements. If the website you try to scrape has many authentication methods (blocking IPs, captchas..) to prevent scraping, you should respect it. Being ethical is important.
What is web scraping?
In the simplest terms, web scraping is the process of extracting information from website(s). With the help of web scraper, you retrieve high volumes of data from the web and transform it into structured data where later can be accessed for further analysis.