Our NLP API provides these functionalities:
- Tokenizer: Segmenting text into words, punctuations marks etc. This is done by applying rules specific to each language. For example, punctuation at the end of a sentence should be split off – whereas “U.K.” should remain one token. Each Doc consists of individual tokens, and we can iterate over them:
- Visualizer: Visualizing a dependency parse or named entities in a text is not only a fun NLP demo – it can also be incredibly helpful in speeding up development and debugging your code and training process. There are two possible types of visualization. Dependency Parse and Entity Recognizer.The dependency visualizer, dep, shows part-of-speech tags and syntactic dependencies. The entity visualizer, ent, highlights named entities and their labels in a text.
- Lemmatization: Assigning the base forms of words. For example, the lemma of “was” is “be”, and the lemma of “rats” is “rat”.
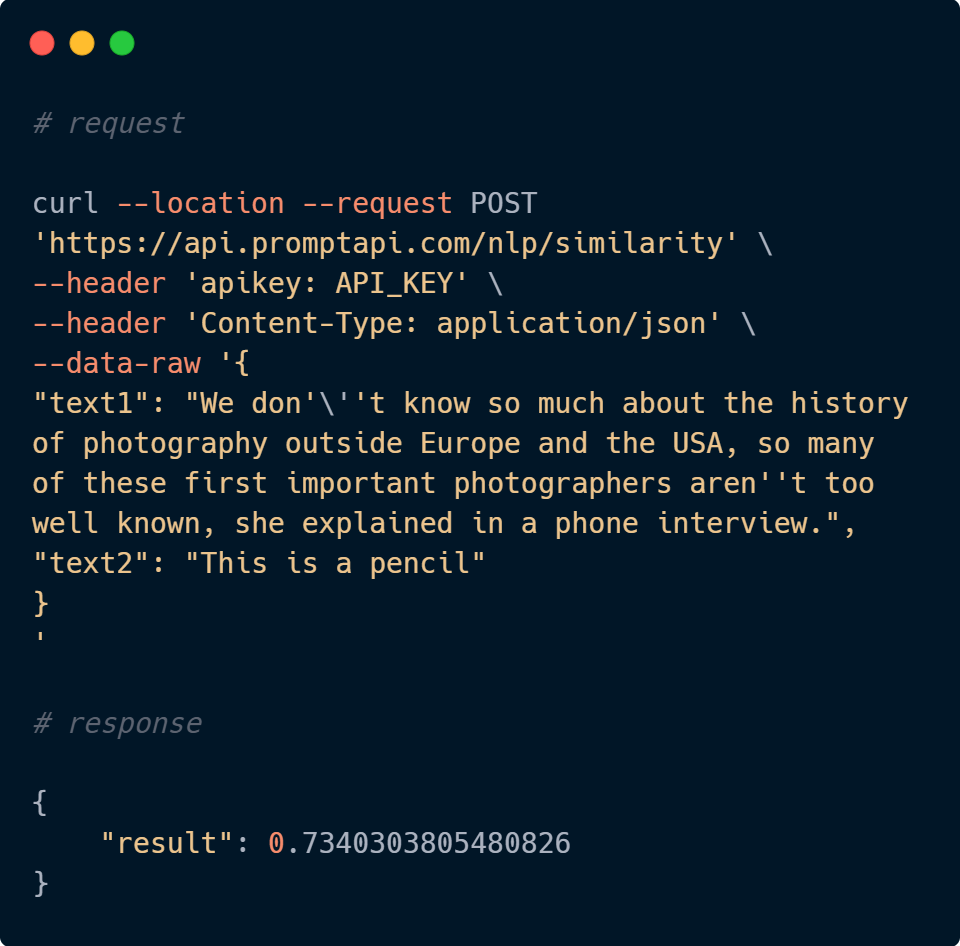
- Similarity: This API is used to compare two texts, and make a prediction of how similar they are. Predicting similarity is useful for building recommendation systems or flagging duplicates. For example, you can suggest a user content that’s similar to what they’re currently looking at, or label a support ticket as a duplicate if it’s very similar to an already existing one.
- Named Entity Extraction: A named entity is a “real-world object” that’s assigned a name – for example, a person, a country, a product or a book title. spaCy can recognize various types of named entities in a document, by asking the model for a prediction. Depending on your language of choice results may differ. So you might consider trying it with different variations.
- Language Detection: Detects the human language of any given text